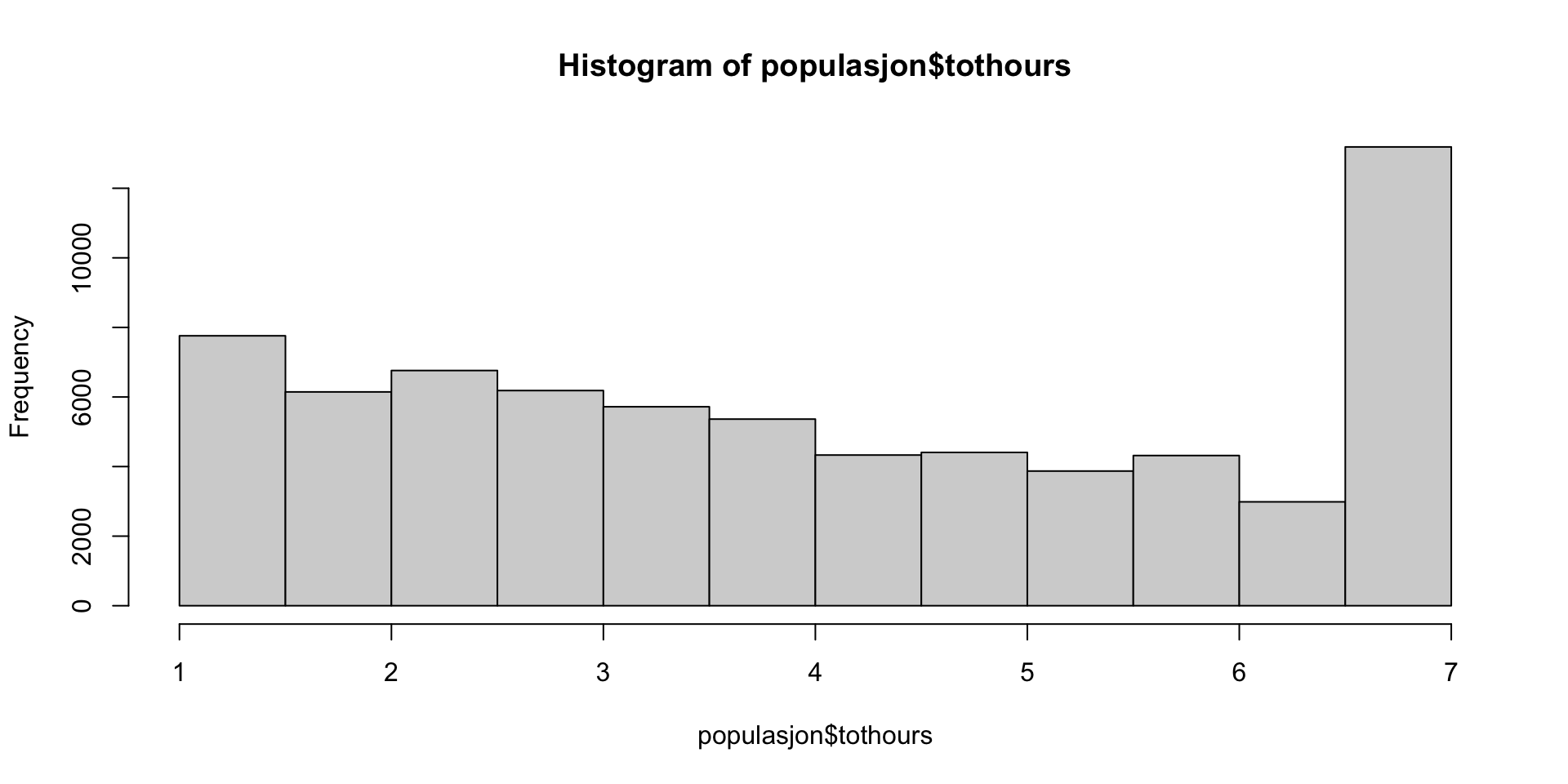
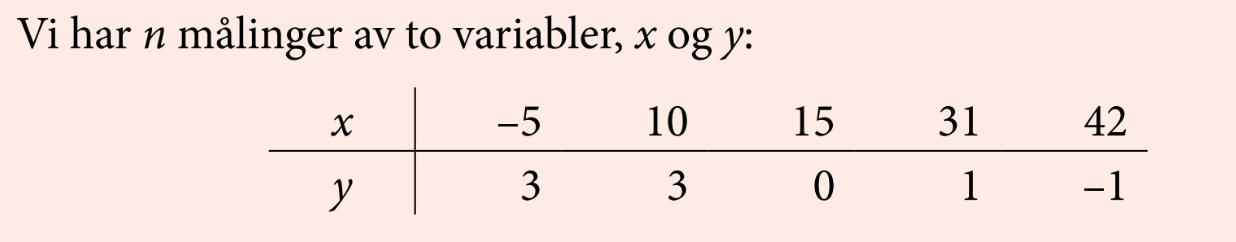En time ekstra daglig mobilbruk gir en forventet nedgang i trivsel på 0.81
Sammenheng trivsel og telefonbruk i et tilfeldig utvalg av 400 15-åringer
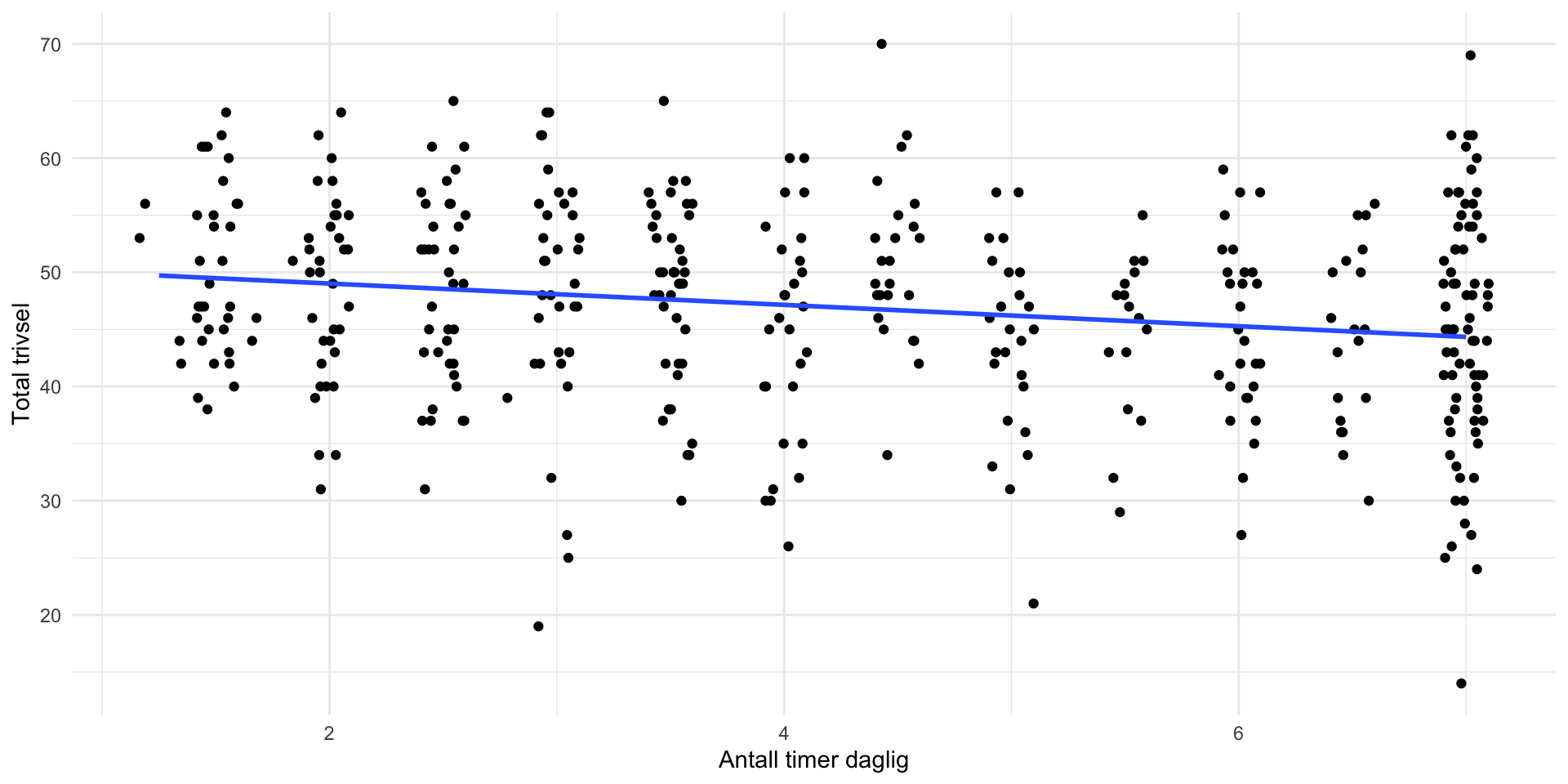
Regresjon i utvalget
term
estimate
std.error
statistic
p.value
(Intercept)
50.89
1.09
46.55
0
tothours
-0.93
0.23
-4.01
0
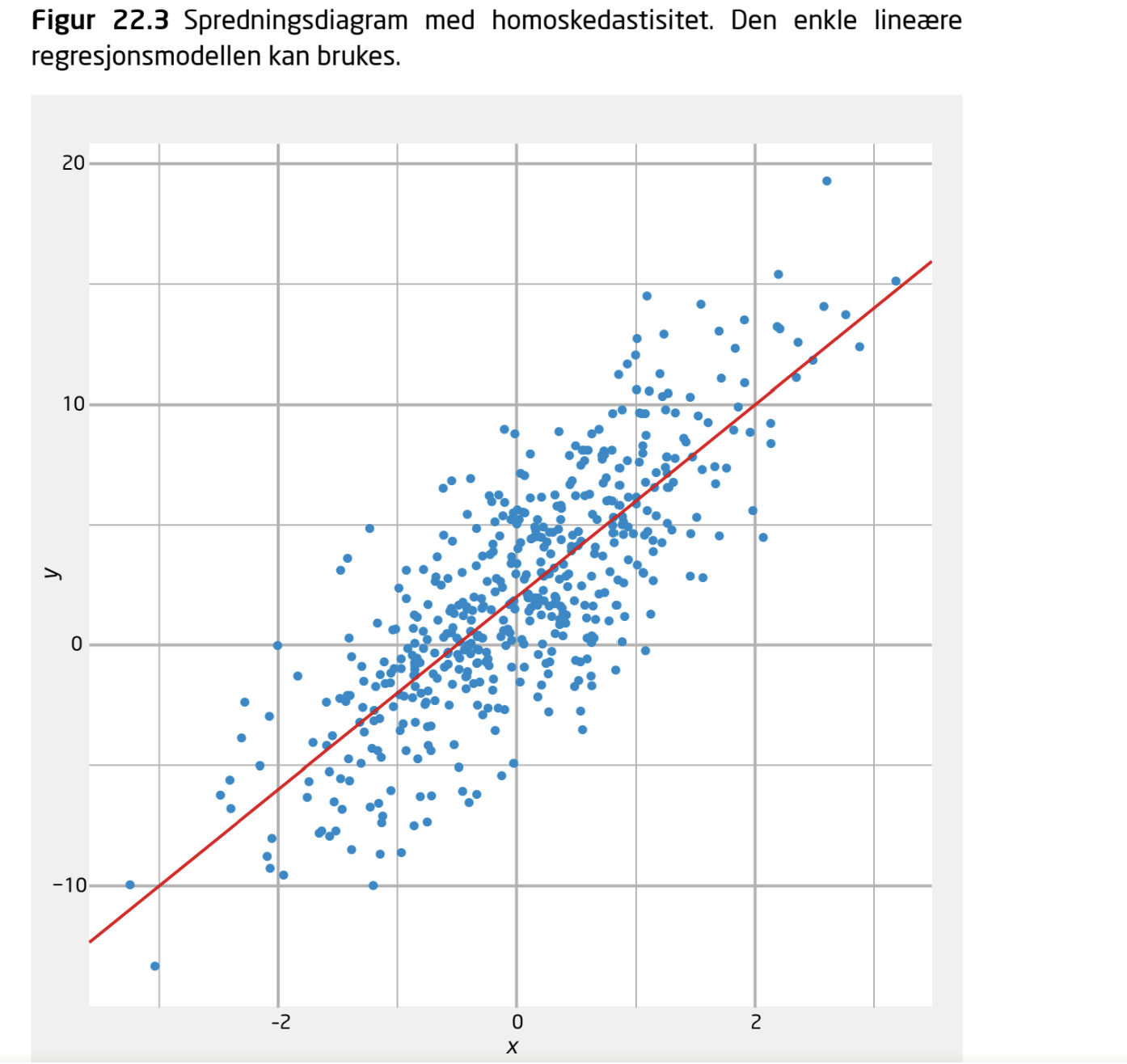
Ganske likt populasjonsverdiene! Vi har linearitet.
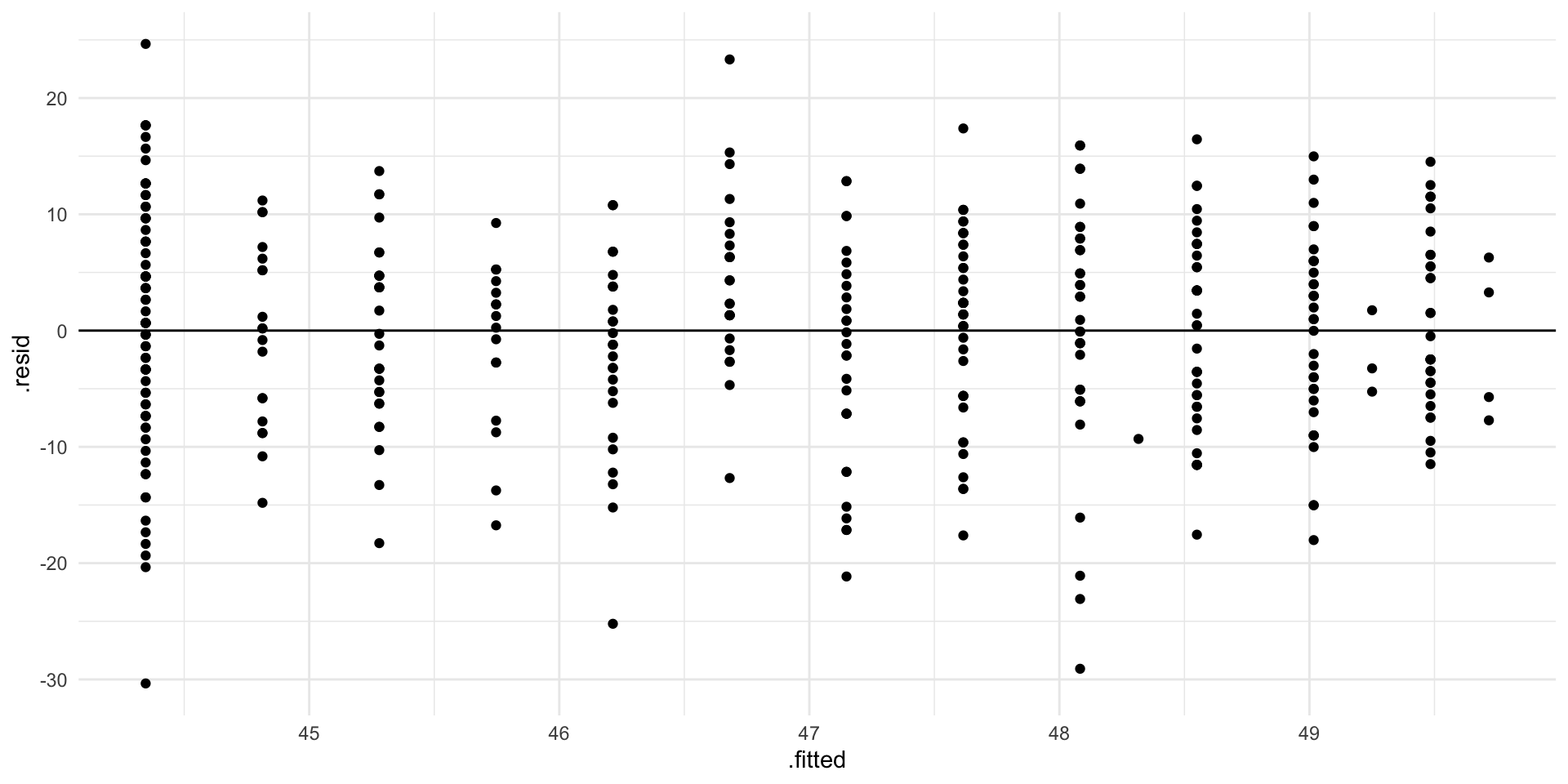
Homoskedastiske feilledd?
Her har vi tilnærmet homoskedastisitet!
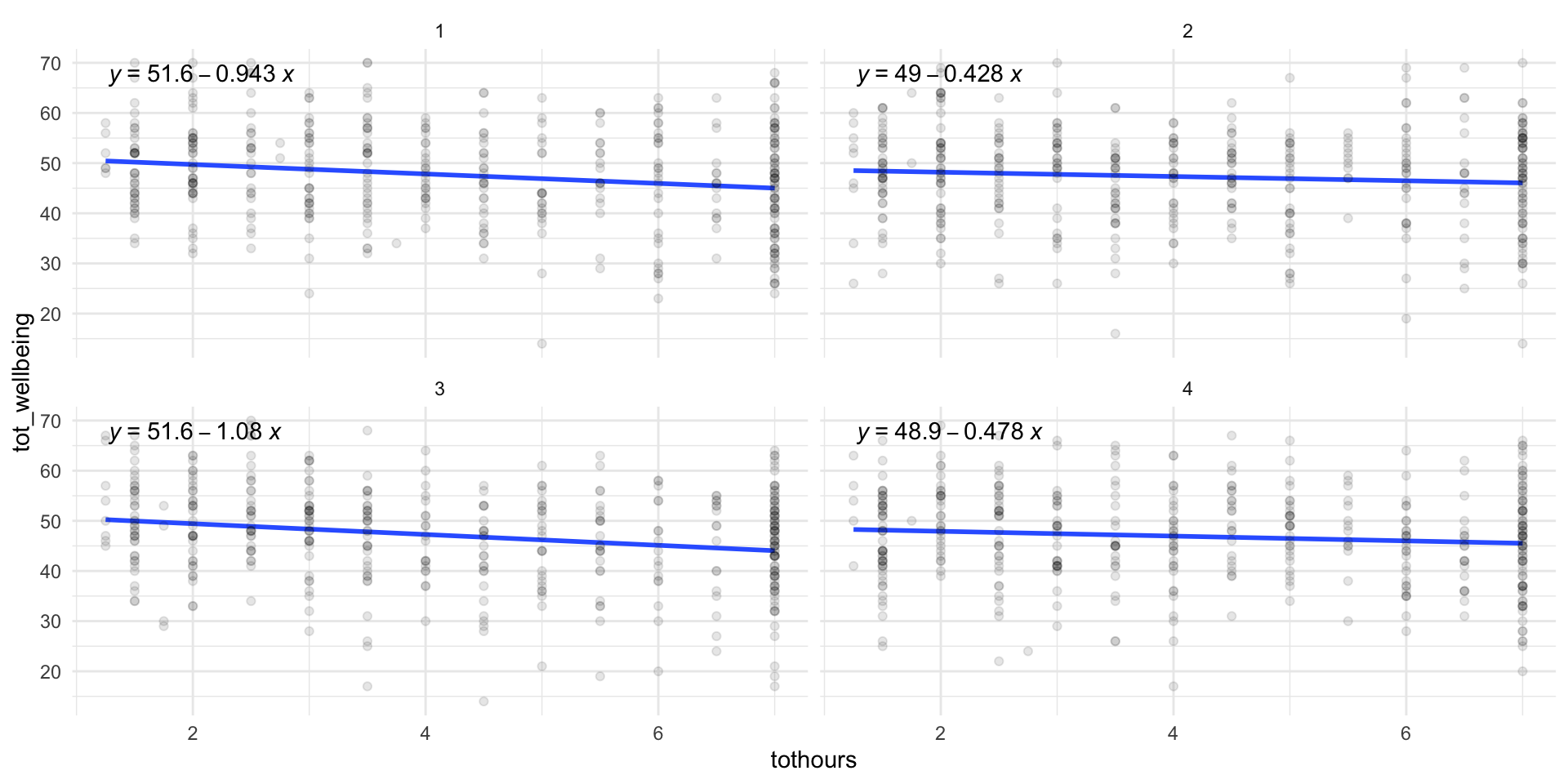
Husk at estimatene er usikre!
Her er fire andre utvalg av størrelse \(n=400\). Vi ser at intercept og slope varierer endel!
Multippel regresjon
Multippel regresjon
En enkel uvidelse av enkel regresjon, der vi har flere uavhengige variable
\[ y = \beta_0+ \beta_1 x_1 + \beta_2 x_2+ \beta_3 x_3+ \epsilon\] Her har vi TRE forklaringsvariabler \(x_1,x_2, x_3\) som forklarer hvorfor \(y\) varierer!
Ceteris paribus
Ceteris paribus [keːˈtɛ.riːsˈpa.rɪ.bʊs] latinsk for “alt annet likt”
I multippel regresjon får vi effekten av en variabel på \(y\), “alt annet likt”. Vi kontrollerer for de andre variablene!
For eksempel: \[ y = 1+ 2 \cdot x_1 - x_2+ 0.5 \cdot x_3+ \epsilon\] Når \(x_1\) øker med 1 enhet, så øker \(y\) med 2 enheter, alt annet likt. Dvs at vi holder \(x_2\) og \(x_3\) fast, og får isolert sammenhengen mellom \(x_1\) og \(y\).
Eksempel: Effekt av telefonbruk på Well-being, kontrollert for kjønn
Gutter har høyere trivsel (6.5 poeng) og lavere mobilforbruk:
# A tibble: 2 × 3
male wbsnitt tothoursnitt
<fct> <dbl> <dbl>
1 0 44.5 4.52
2 1 51.0 3.89
Vi tar med kjønn som forklaringsvariabel. Dette er en kategorisk variabel, vi koder den med en dummy variabel: male=0 betyr jente, male=1 betyr gutt.
Kategoriske variabler og dummy-koding
kategoriske variabler kan kodes med dummyvariabler i regresjon. Dersom vi har \(K\) kategorier, trenger vi \(K-1\) dummy variabler:
Kjønn: \(K=2\). Vi har \(K-1=2-1=1\) dummy variabel.
USA politisk tilørighet: Dem, Rep, Ind: \(K=3\). Vi har \(K-1=2-1=2\) dummy variabler. For eksempel kan vi har \(R=1\) hvis republikaner, og \(D=1\) hvis demokrat. Vi trenger ikke \(Ind\), siden dersom \(R=0\) og \(D=0\) så vet vi at det er en independent velger.
Effekten av telefonbruk er litt mindre når vi kontrollerer for kjønn (-0.934 \(\rightarrow\) -0.688 )
Og effekt av kjønn på trivsel, når vi kontrollerer for telefonbruk, er lavere nå, 6.07. Så noe av den observerte trivselforskjellen på 6.5 kan forklares ved at guttene er mindre på mobil, og at mobil ikke er bra for wellbeing!
ANOVA
ANOVA analysis of variance
I intro statistikk så lærer man anova. - Du har flere grupper i populasjonen - Du lurer på om \(y\) har samme gjennomsnitt i alle gruppene - \(H_0:\mu_1=\mu_2=\cdots=\mu_g\) - Alternativhypotesen er at gruppegjennomsnittene ikke alle er like!
Eksempel
Vi antar at i utvalget var det 4 skoler. Vi ønsker å teste om well-being er den samme på alle skolene: