library(tidyverse)
set.seed(1)
gruppe <- sample(c("I","K"), size=100,replace=T)
konsentrasjon <- 10+as.numeric(gruppe=="I")+runif(length(gruppe), -6,6) %>% round(0)
minedata <- data.frame(gruppe, konsentrasjon)Quiz 19.mars
- Forklar hvorfor publikasjonsbias kan være en av årsakene til replikasjonskrisen.
Svar: Det er vanskelig å replikere en studie som er en falsk positiv. Falske positive er overrepresentert i den publiserte litteraturen, grunnet publikasjonsbias.
- Hva regnes som en stor effektstørrelse for Cohens \(d\)?
Svar: I mange felt er \(d\) større ennn .5 regnet som stor.
- Cohen \(d=0.2\) for en intervensjon, tolk dette tallet i en setning som inneholder ordene “standardavvik” og “økning i gjennomsnittsscore”.
Svar: Forskjellen mellom intervensjon og kontroll tilsvarer en økning i gjennomsnittscore på 0.2 standardavvik.
- En mindfulness-intervensjon gjør at konsentrasjonen i intervensjonsgruppa er 3 poeng høyere enn i kontrollgrupa. Hvis den poolede standardavviket \(s_p\) er 10 poeng, hva er da effektstørrelsen?
Svar: \(d =\frac{\overline{x_I}-\overline{x_K}}{s_p}=3/10=0.3\)
- Vi genererer et datasett som måler konsentrasjon på en skala 1-20 etter en mindfulness-intervensjon:
Hvor mange deltagere var i kontroll og i intervensjonsgruppa? Hint:
table(gruppe)gruppe
I K
49 51 - Lag et histogram over konsentrasjon
hist(minedata$konsentrasjon)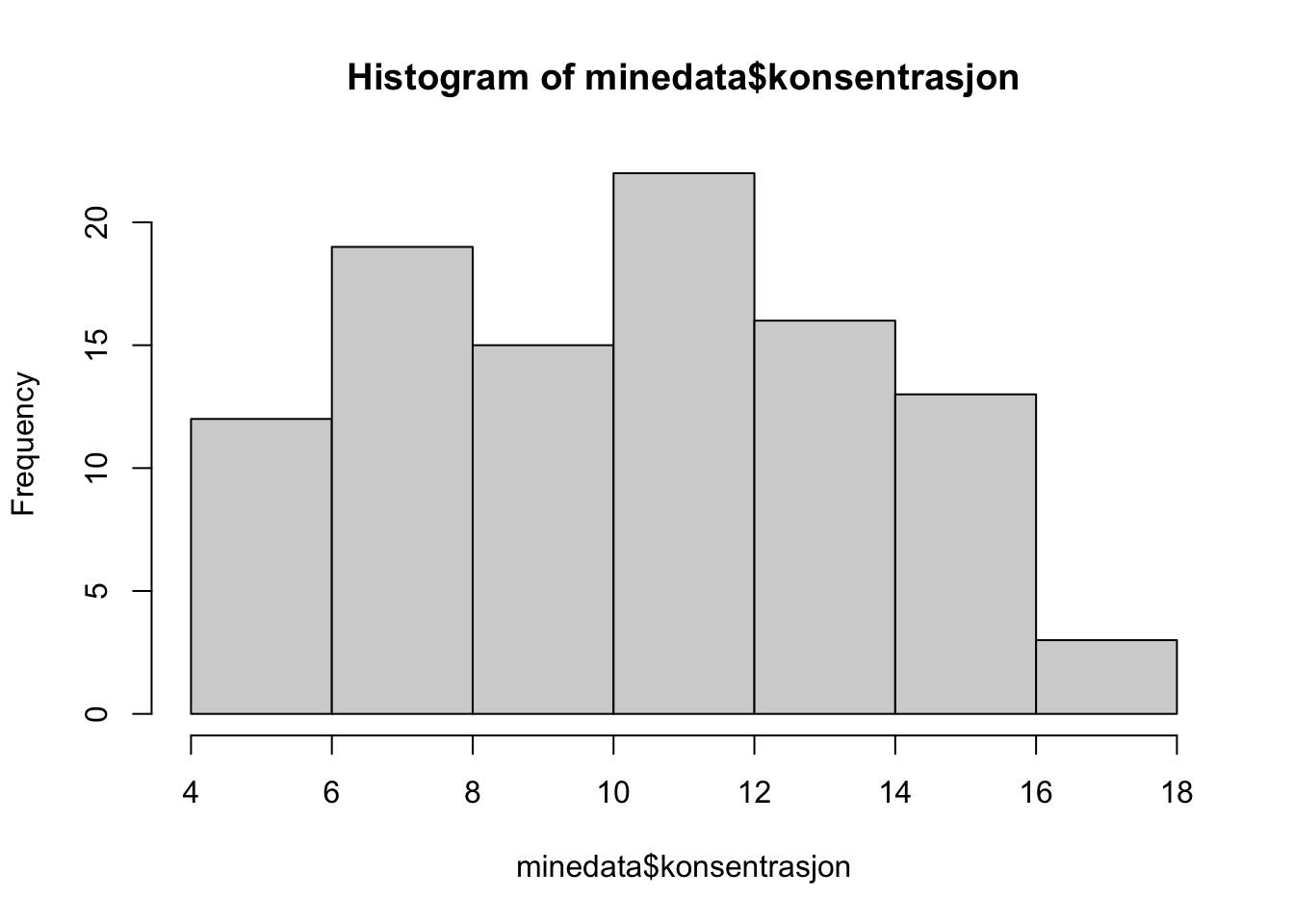
- Hva er max verdi av konsentrasjon?
max(minedata$konsentrasjon)[1] 17- Lag et boksplot over konsentrasjon og bruk det til å anslå interkvartilbredden.
boxplot(minedata$konsentrasjon)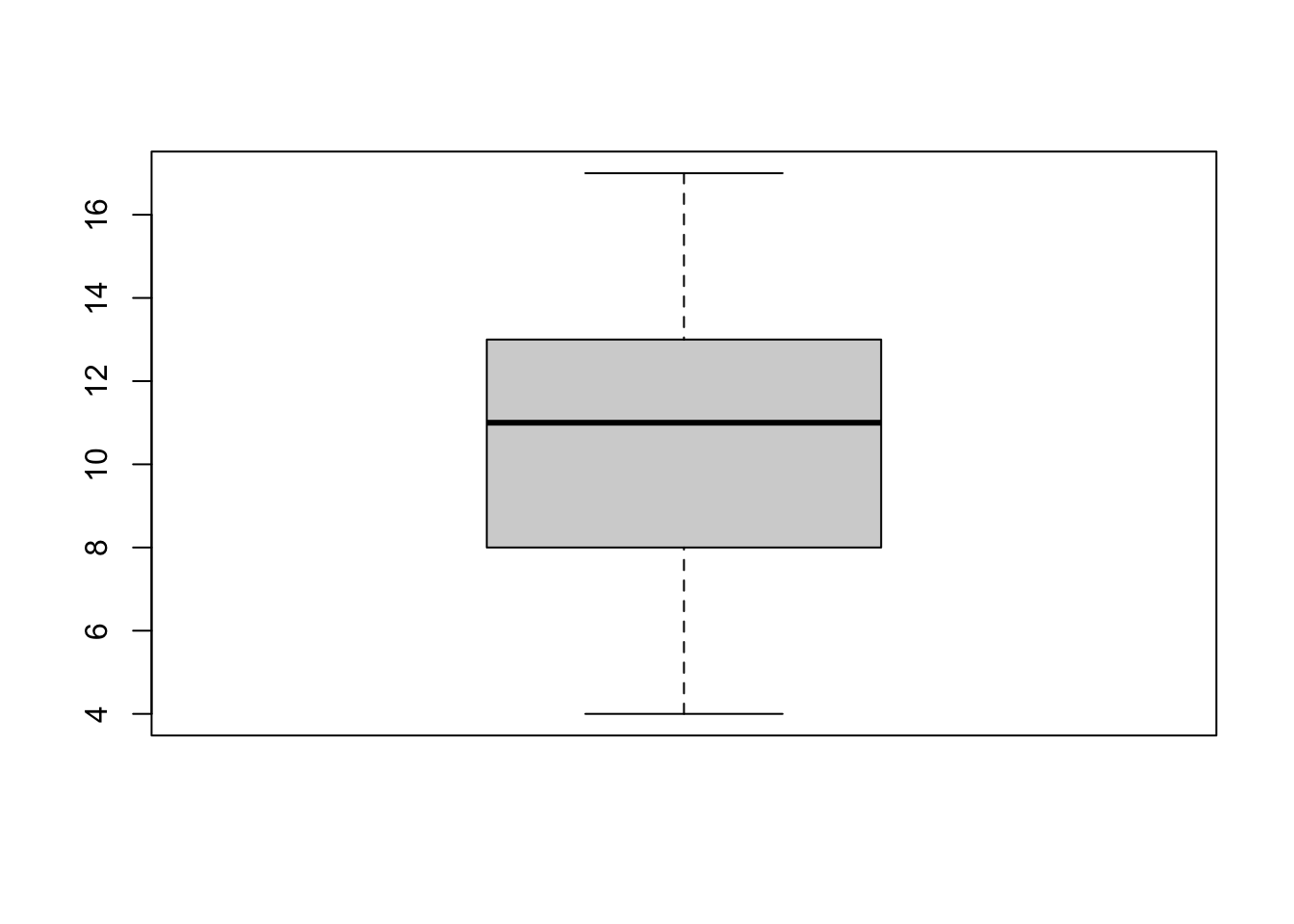
- Hva er standardavviket til konsentrasjon?
boxplot(minedata$konsentrasjon)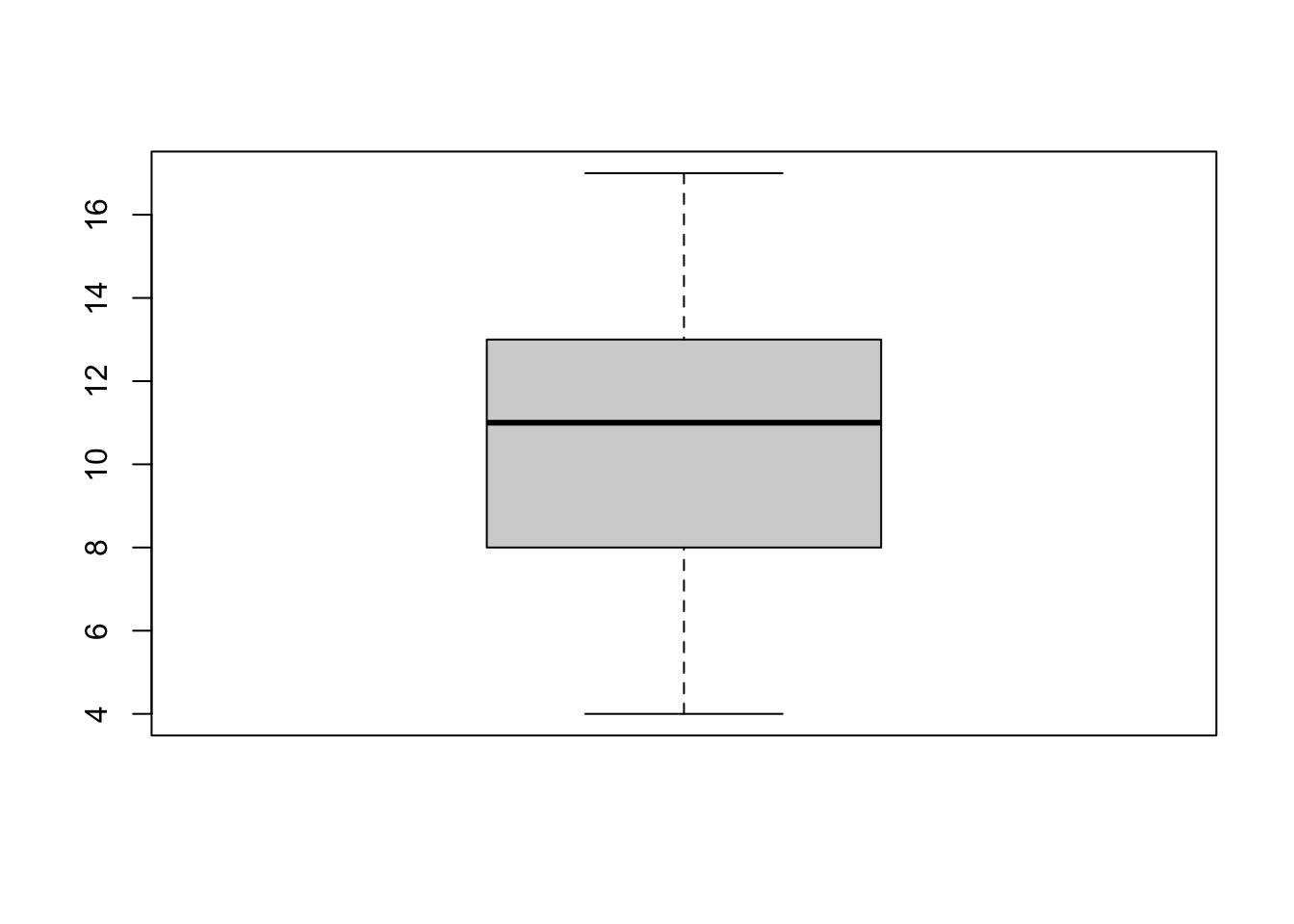
- Er det signifikant forskjell i konsentrasjon i de to gruppene? Bruk en t-test
t.test(konsentrasjon~gruppe, data=minedata)
Welch Two Sample t-test
data: konsentrasjon by gruppe
t = 1.2389, df = 97.632, p-value = 0.2184
alternative hypothesis: true difference in means between group I and group K is not equal to 0
95 percent confidence interval:
-0.4985509 2.1552136
sample estimates:
mean in group I mean in group K
11.12245 10.29412 Nei ikke signifikant forskjell , p-verdien er større enn .05
- Hva var differansen i gjennomsnitt?
Svar: 11.12245 - 10.29412 =0.83 poeng
- Beregn cohens d for effektstørrelsen av intervensjonen.
library(psych)
cohen.d(konsentrasjon~gruppe, data=minedata)Svar: d=0.25
- Hva er konfidensintervallet for \(d\). Gi en tolkning av det faktum at det inneholder \(0\).
Svar: Konfidensintervallet går fra -0.14 til 0.64 At 0 er inneholdt betyr at vi effektstørrelsen ikke er signifikant forskjellig fra 0.
- Vi Lager et nytt simulert datasett for effekt av konsentrasjon på eksamensresultat:
set.seed(1)
poeng <- 25+2*konsentrasjon+rnorm(length(konsentrasjon), mean=0, sd=10)
eksamendata <- data.frame(poeng, konsentrasjon)- Plott konsentrasjon mot eksamensresultat og beregn korrelasjonen
plot(eksamendata$konsentrasjon, eksamendata$poeng)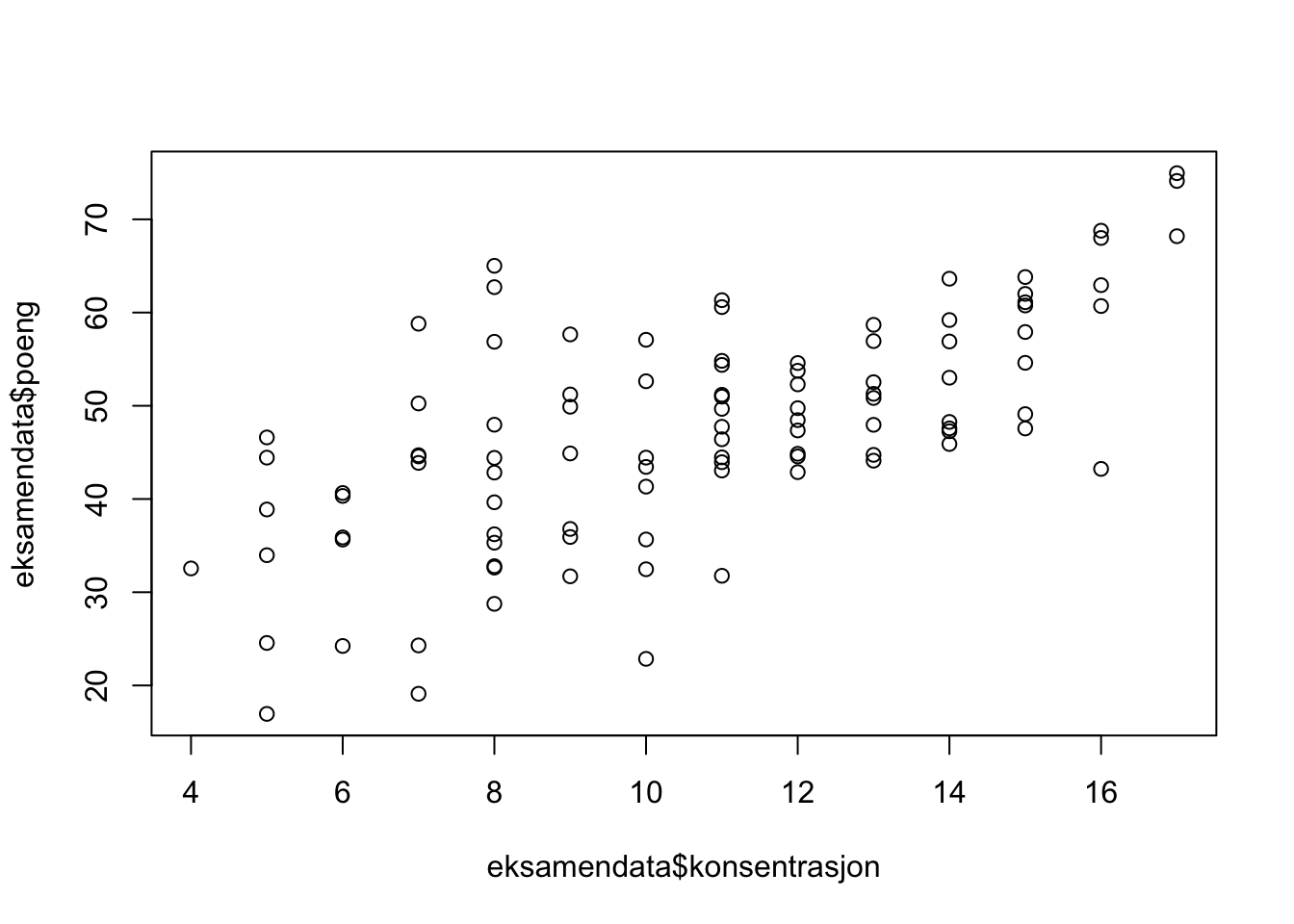
- Estimer regresjonsmodellen \(Poeng=\beta_0+ \beta_1 konsentrasjon + \epsilon\) og tolk stigningstallet \(\beta_1\) på en lettfattelig måte
model <- lm(poeng~konsentrasjon, data=eksamendata)
summary(model)
Call:
lm(formula = poeng ~ konsentrasjon, data = eksamendata)
Residuals:
Min 1Q Median 3Q Max
-23.0078 -6.1458 0.0825 5.8221 23.8069
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 22.6031 3.0129 7.502 2.88e-11 ***
konsentrasjon 2.3258 0.2688 8.651 1.02e-13 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.961 on 98 degrees of freedom
Multiple R-squared: 0.433, Adjusted R-squared: 0.4272
F-statistic: 74.84 on 1 and 98 DF, p-value: 1.015e-13Svar: En økning i konsentrasjon på 1 poeng gjir en forventet økning i eksamensscore på 2.33 poeng.
- Hva er forklaringskraften til modellen?
Svar: 0.43
- Sjekk at de tre forutsetningene (linearitet, homoskedastisitet og normalitet av residualer) ser ut til å være oppfylt
library(performance)
check_model(model, check=c("linearity", "homogeneity", "normality"))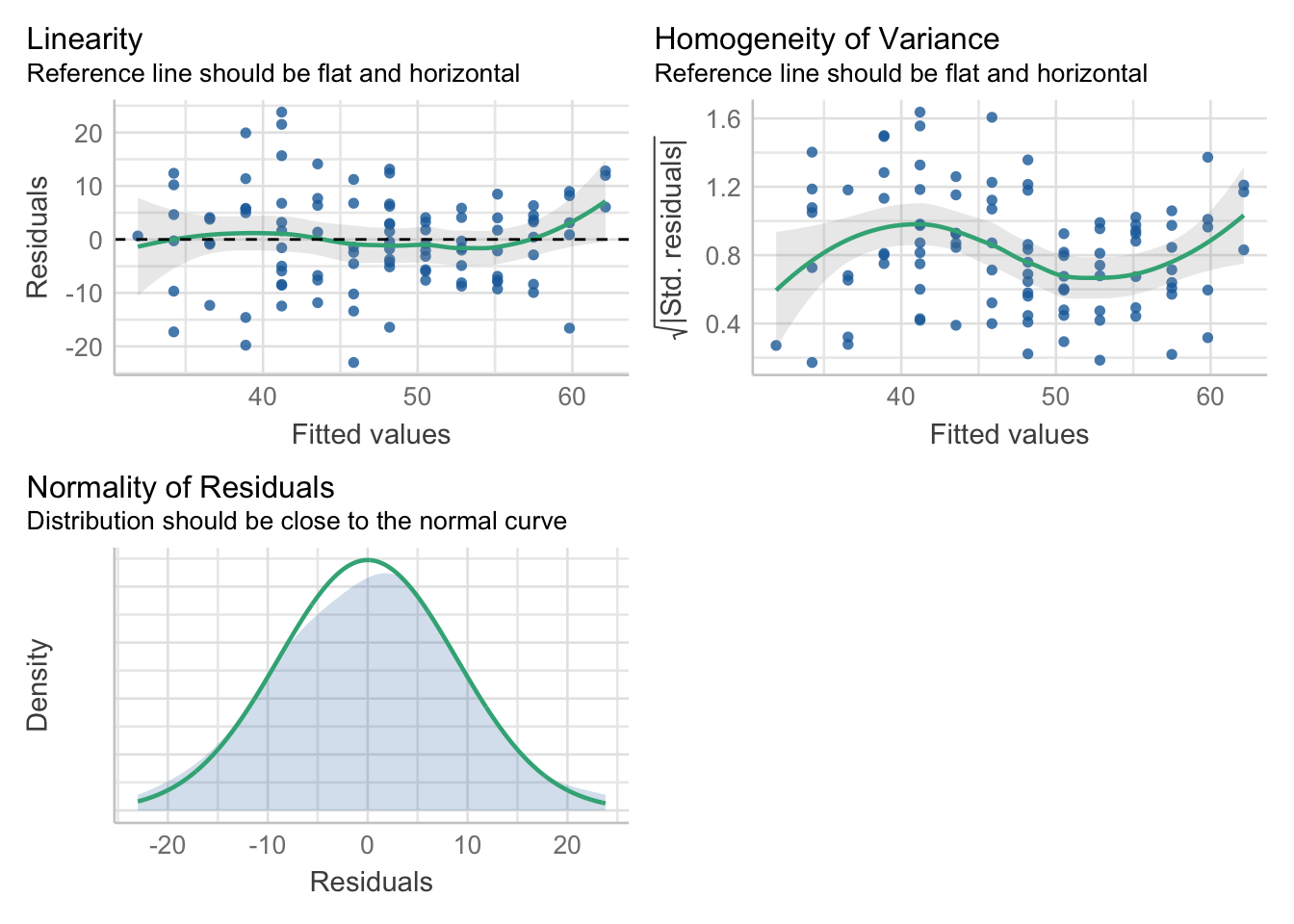
Svar: Ja de grønne linjene i de to første panelen er omtrent horisontale, og fordelingen til residualene følger tilnærmet den grønne normalfordelingen i det siste panelet.
- Vi simulerer poengscore på ny, men nå med et ikke-normalt residual (khi-kvadrat fordelt)
set.seed(1)
poeng <- 25+2*konsentrasjon+rchisq(length(konsentrasjon), df=2)
eksamendata <- data.frame(poeng, konsentrasjon)
nymodell <- lm(poeng~konsentrasjon, data=eksamendata)Kontroller at normalitetsantagelsen er brutt:
check_model(nymodell, check=c("normality"))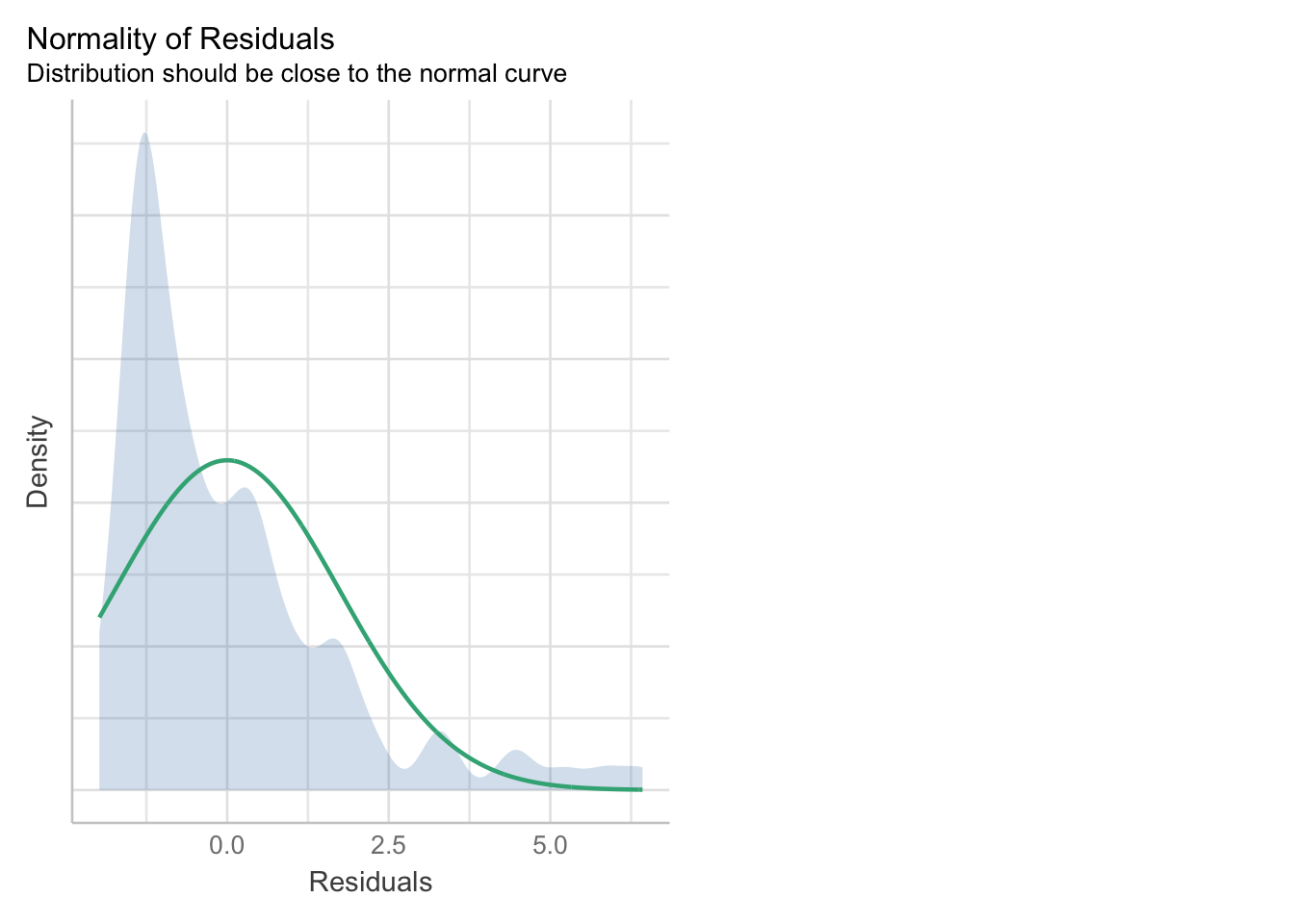
Svar: Fordelingen til residualene avviker fra den grønne normalfordelte linja, så her er normalitetsantagelsen brutt.