R for digital samling 1
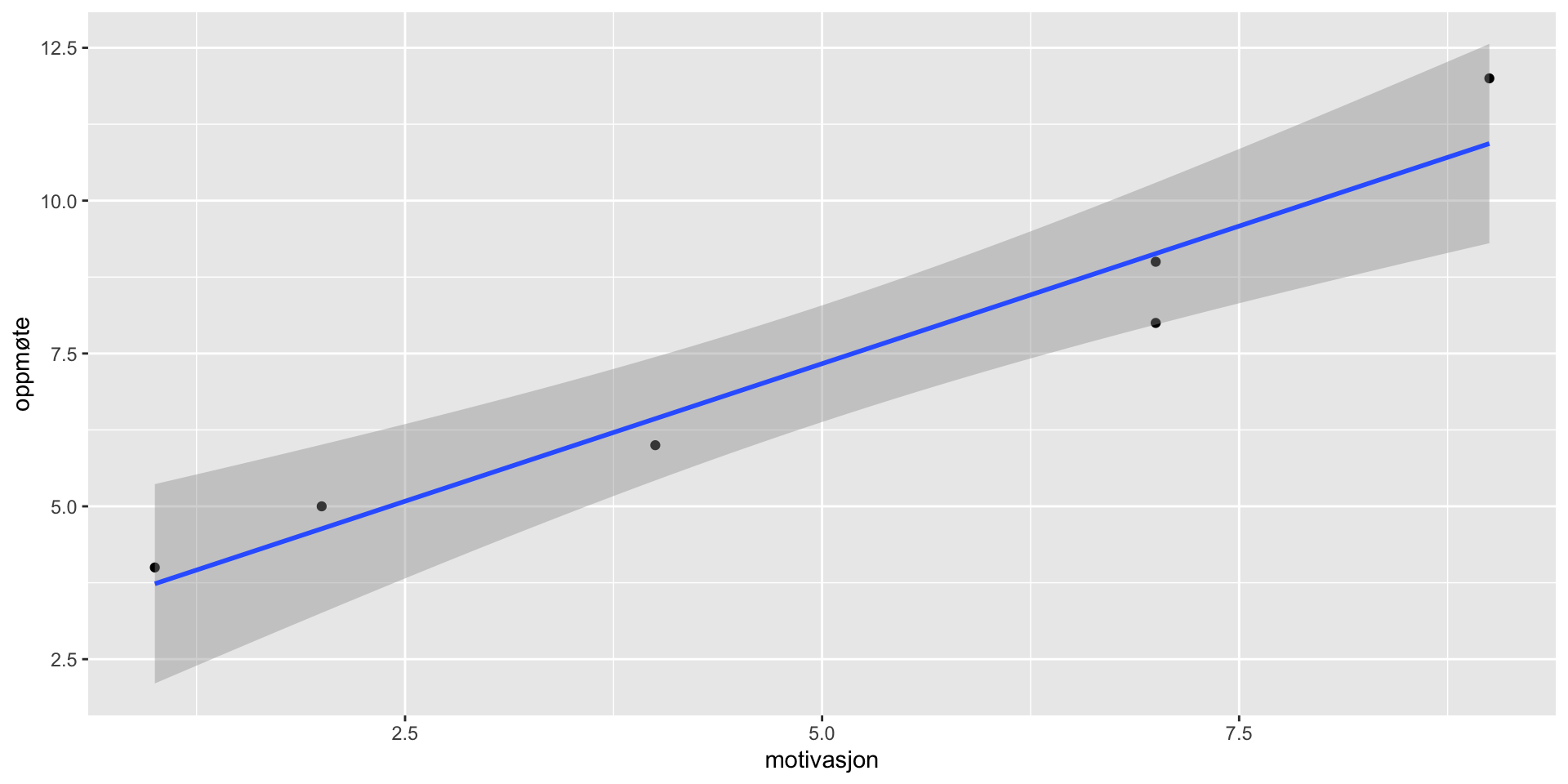
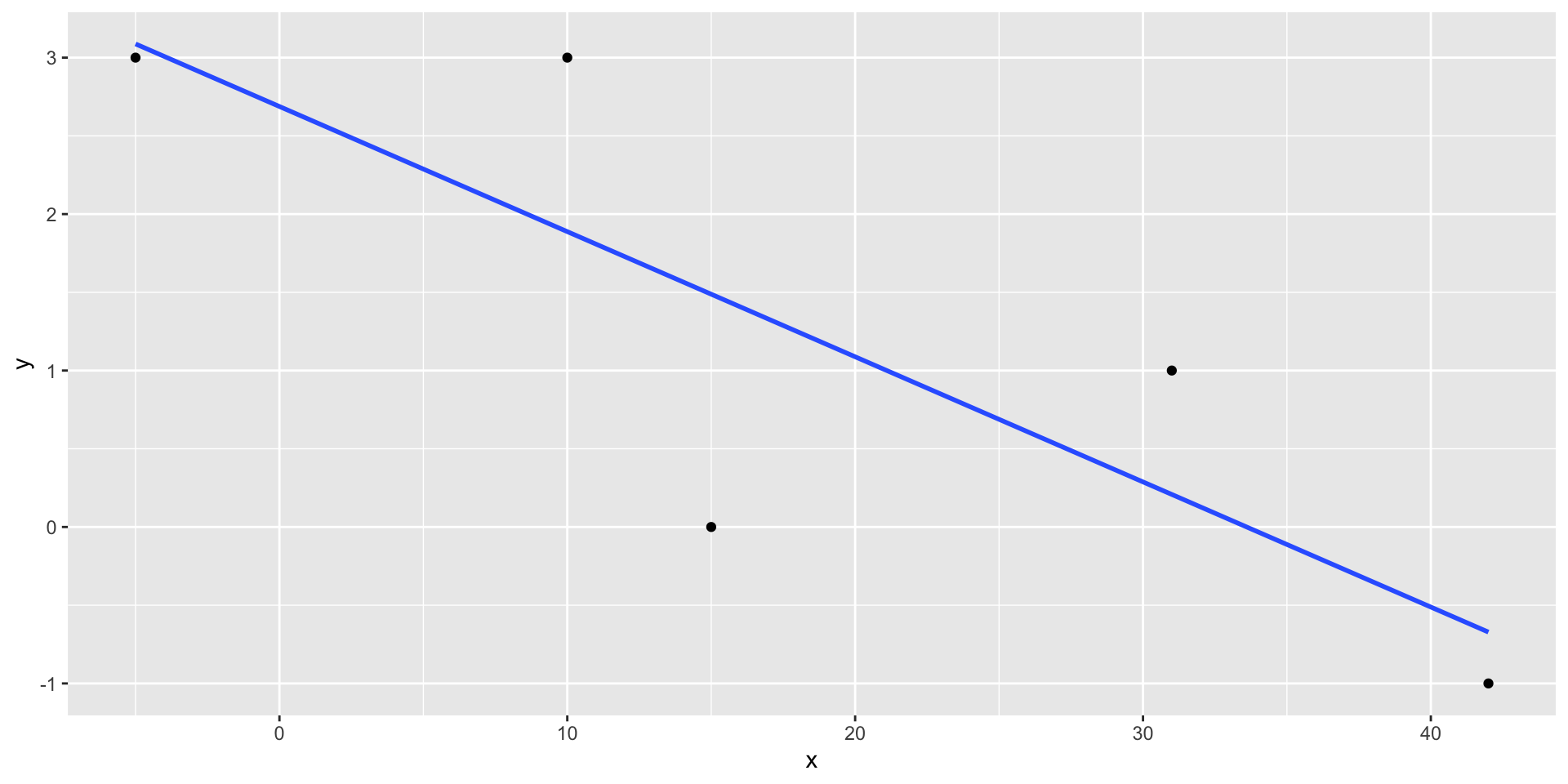
Lekeeksempel
Predikere ny verdi for \(x=20\)
1
1.088017 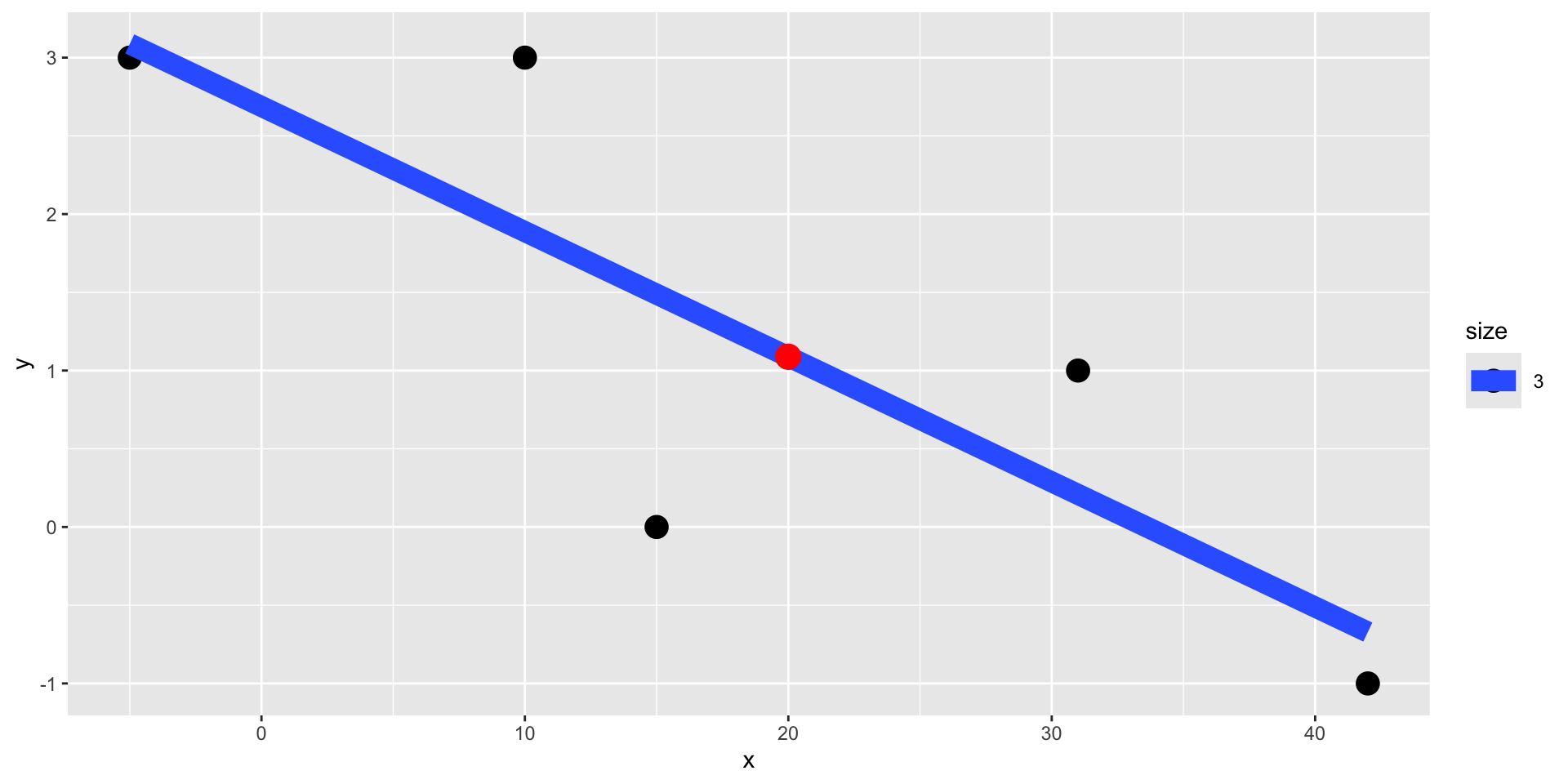
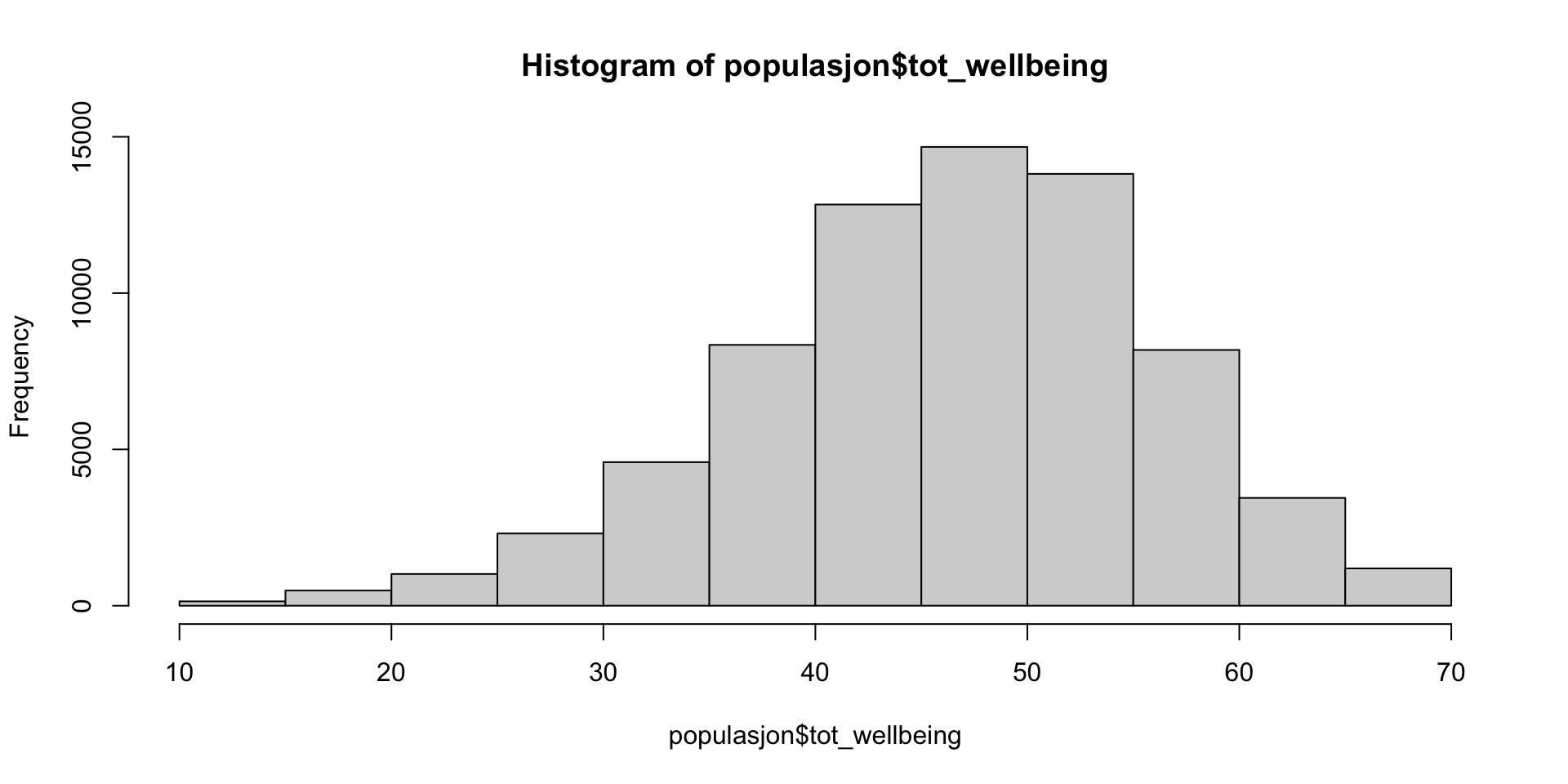
Trivsel og well-being populasjon
Last ned datasettene først! Se Data til venstre i margen
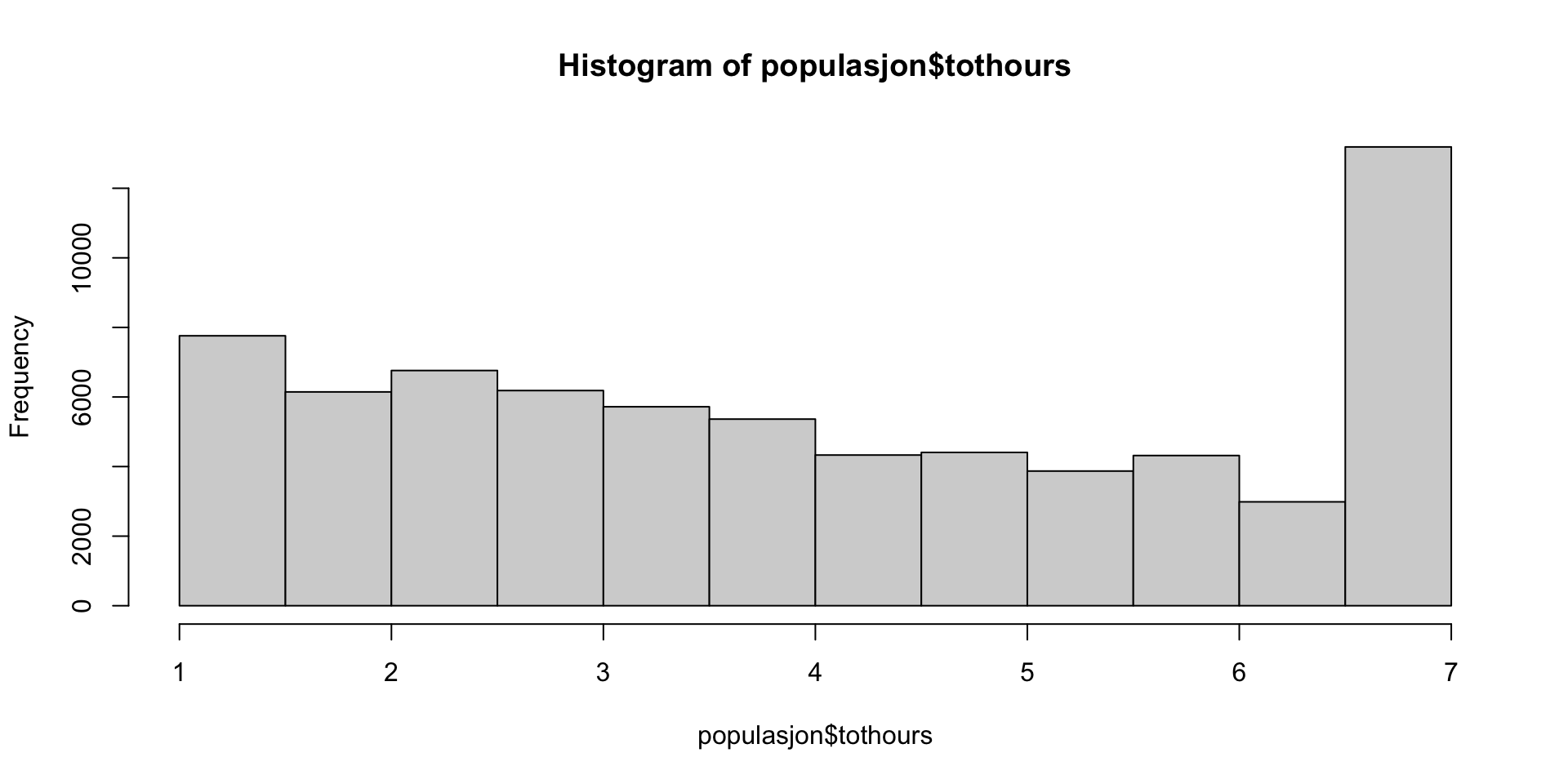
Regresjon i utvalget (last ned først)
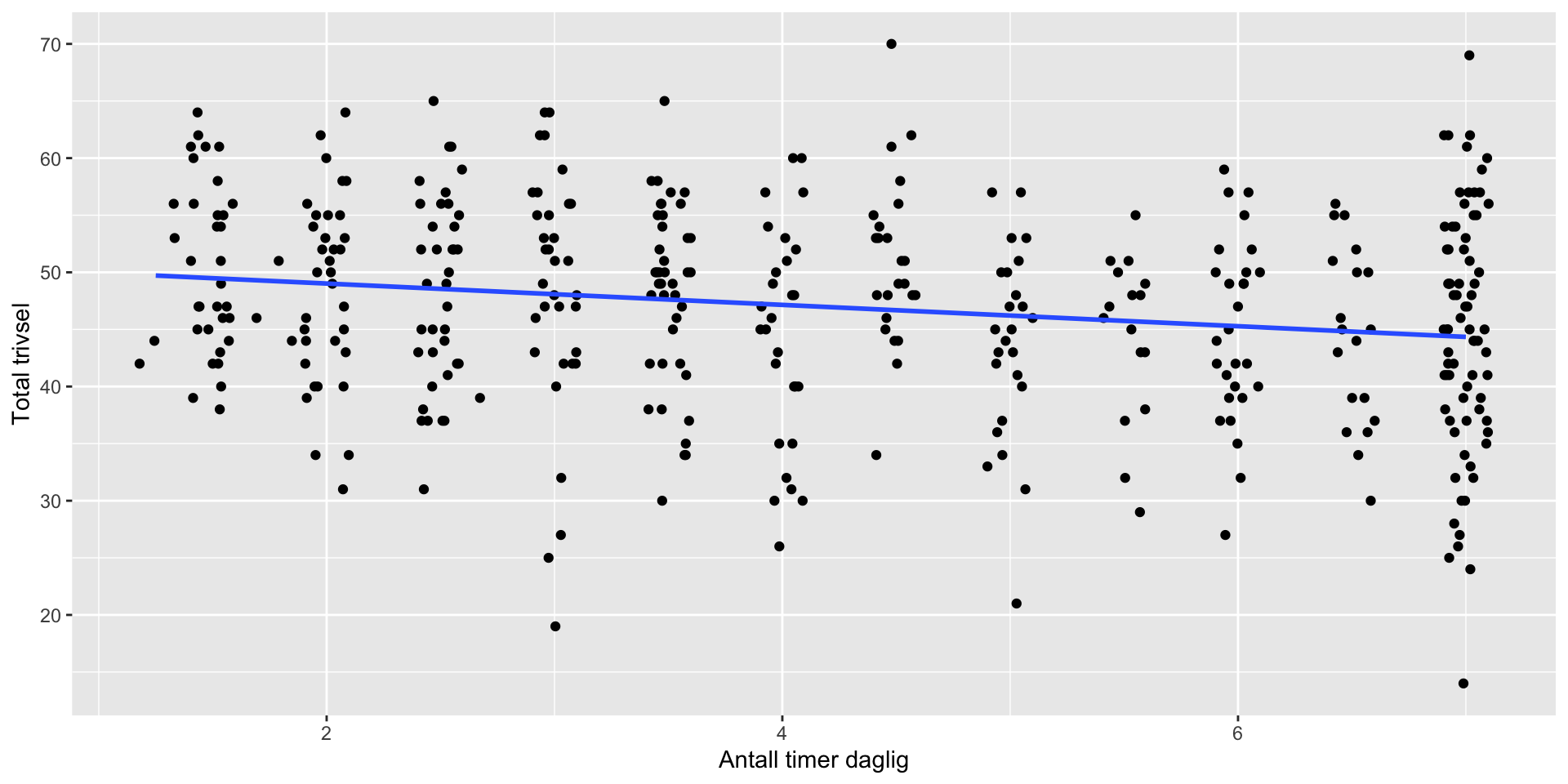
Oppg 2
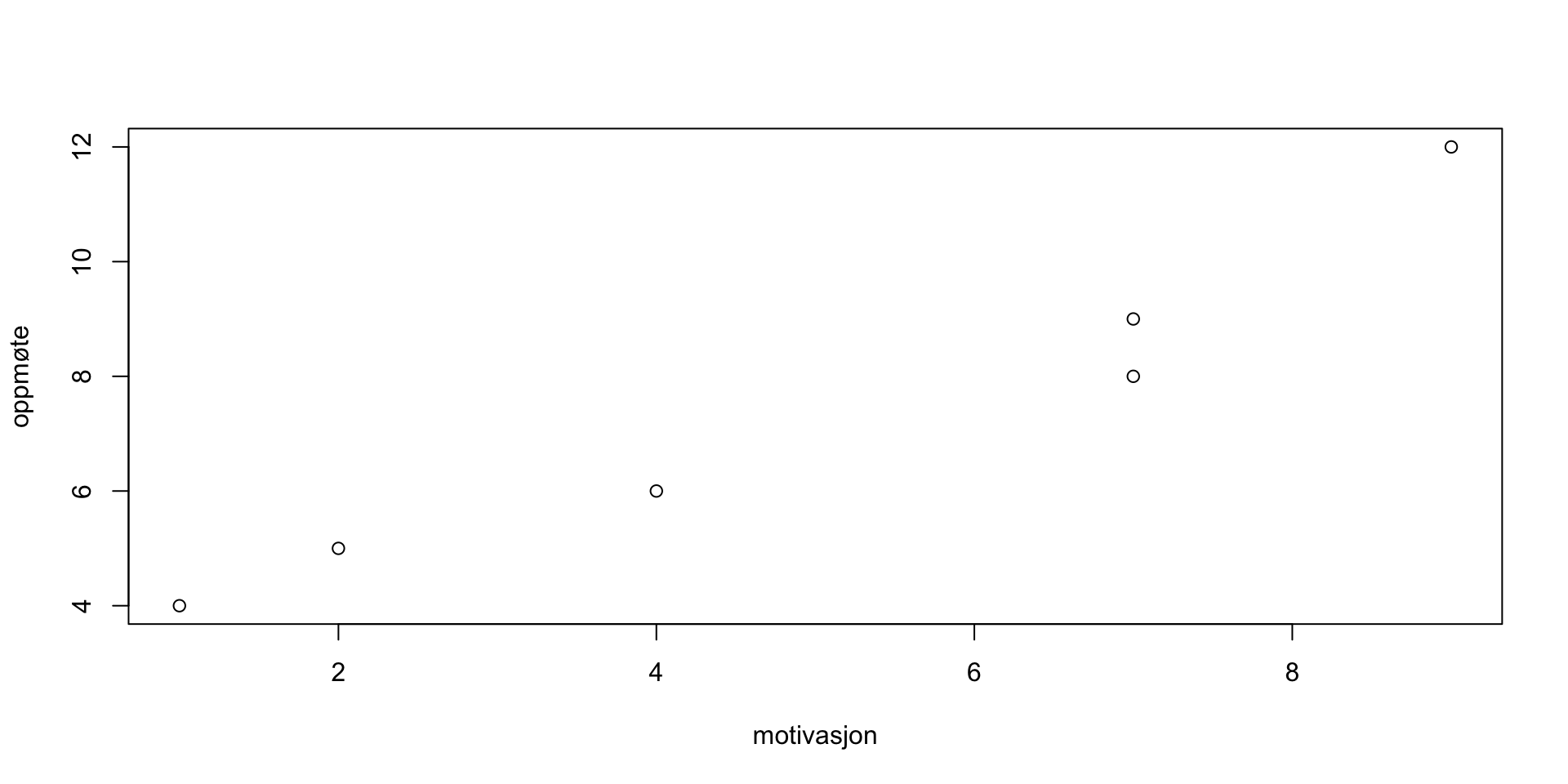
Oppg 4
Call:
lm(formula = oppmøte ~ motivasjon)
Coefficients:
(Intercept) motivasjon
2.833 0.900